Introduction
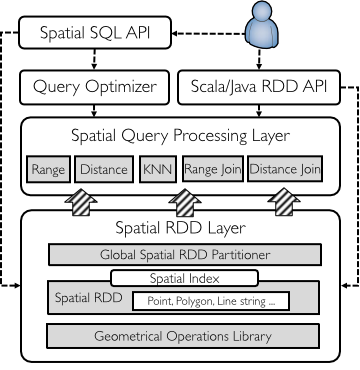
GeoSpark is a cluster computing system for processing large-scale spatial data. GeoSpark extends Apache Spark / SparkSQL with a set of out-of-the-box Spatial Resilient Distributed Datasets (SRDDs)/ SpatialSQL that efficiently load, process, and analyze large-scale spatial data across machines.
Source code
I implemented GeoSpark into Apache Spark and SparkSQL. Source code is hosted on Github: Source code, Project website
Reputation
-
GeoSpark is the defacto spatial data processing framework on top of Apache Spark.
-
GeoSpark had been recognized by Apache Spark Official Third Party Projects List since Sept.2016. The link was removed in Aug. 2018 due to the conflict with Spark trademark (see this commit)
-
GeoSpark has > 200K overall website visits and > 10K monthly downloads.
-
Users and contributors include Facebook, Apple, Uber, MoBike, and numerous startups
-
GeoSpark in production (video), from Gyana, a British Location Inteligence company
-
GeoSpark received an evaluation from PVLDB 2018 paper How Good Are Modern Spatial Analytics Systems?, written by Varun Pandey, Andreas Kipf, Thomas Neumann, Alfons Kemper (Technical University of Munich), quoted as follows:
GeoSpark comes close to a complete spatial analytics system. It also exhibits the best performance in most cases.
Selected publications
GeoSpark is a full-fledged big geospatial data analytics system that provides
- Data generation (GeoSparkSim, MDM 2019)
- Data managemenet and query processing (GeoSpark, Geoinformatica 2019)
- Visulization (GeoSparkViz, SSDBM 2018, an extended version is under revision by VLDB Journal)
Jia Yu
PhD Candidate
Jia Yu is a PhD candidate at Arizona State University. He will be an assistant professor in Computer Science at Washington State University School of Electrical Engineering and Computer Science from Fall 2020. His research interests include database systems, distributed data systems and geospatial data management.