Introduction
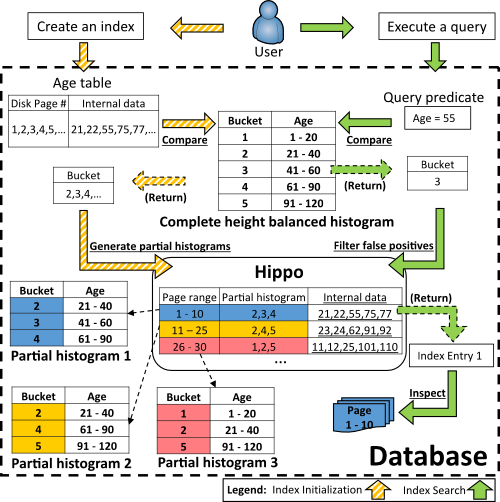
Hippo is a fast, yet scalable, database indexing approach. It significantly shrinks the index storage and mitigates maintenance overhead without compromising much on the query execution performance. Hippo stores disk page ranges instead of tuple pointers in the indexed table to reduce the storage space occupied by the index. It maintains simplified histograms that represent the data distribution and adopts a page grouping technique that groups contiguous pages into page ranges based on the similarity of their index key attribute distributions. When a query is issued, Hippo leverages the page ranges and histogram-based page summaries to recognize those pages such that their tuples are guaranteed not to satisfy the query predicates and inspects the remaining pages.
Highlight
Publications: PVLDB 2016 (research), ICDE 2017 (demo), SSTD 2017 (research)
Collaborators: Mohamed Sarwat (Arizona State University)
Highlight: Hippo is a PostgreSQL 9.6 built-in index
Source code
I implemented Hippo index into PostgreSQL kernel. Source code is hosted on Github: https://github.com/DataSystemsLab/hippo-postgresql
Demo video
I implemented a demo system using Hippo-spatial as the backend. Demo video is hosted on Youtube: https://www.youtube.com/watch?v=wWaOK2-9k9A
Presentation
I presented Hippo index in VLDB 2017. Here is the pre-presentation video: http://www.public.asu.edu/~jiayu2/video/vldb2017-presentation.mp4