Introduction
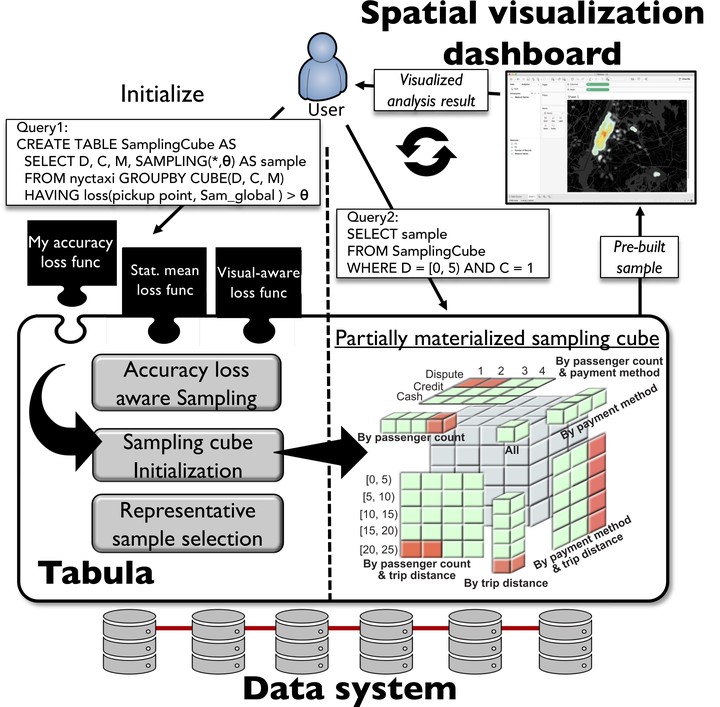
Tabula is a middleware that runs on top of a SQL data system with the purpose of increasing the interactivity of geospatial visualization dashboards. The proposed system adopts a sampling cube approach that stores pre-materialized spatial samples and allows users to define their own accuracy loss function such that the produced samples can be used for various user-defined visualization tasks. The system ensures that the difference between the sample fed into the visualization dashboard and the raw query answer never exceeds the user-specified loss threshold. To reduce the number of cells in the sampling cube and hence mitigate the initialization time and memory utilization, the system employs two main strategies: (1) a partially materialized cube to only materialize local samples of those queries for which the global sample (the sample drawn from the entire dataset) exceeds the required accuracy loss threshold. (2) a sample selection technique that finds similarities between different local samples and only persists a few representative samples. Based on extensive experimental evaluation, Tabula can bring down the total data-to-visualization time (including both data-system and visualization times) of a heat map generated over 700 million taxi rides to 600 milliseconds with 250 meters user-defined accuracy loss. Besides, Tabula costs up to two orders of magnitude less memory footprint (e.g., only 800 MB for the running example) and one order of magnitude less initialization time than the fully materialized sampling cube approach.
Highlight
Publications: ICDE 2020 (research), VLDB 2020 (demo)
Collaborators: Mohamed Sarwat (Arizona State University)
Highlight: Tabula is implemented in Apache Spark SQL
Source code
I implemented Tabula in Apache Spark SQL. Source code is hosted on Github: https://github.com/DataSystemsLab/tabula