Introduction
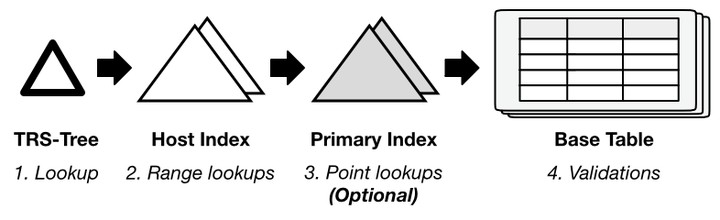
Database administrators construct secondary indexes on data tables to accelerate query processing in relational database management systems (RDBMSs). These indexes are built on top of the most frequently queried columns according to the data statistics. Unfortunately, maintaining multiple secondary indexes in the same database can be extremely space consuming, causing significant performance degradation due to the potential exhaustion of memory space. In this paper, we demonstrate that there exist many opportunities to exploit column correlations for accelerating data access. We propose Hermit, a succinct secondary indexing mechanism for modern RDBMSs. Hermit judiciously leverages the rich soft functional dependencies hidden among columns to prune out redundant structures for indexed key access. Instead of building a complete index that stores every single entry in the key columns, Hermit navigates any incoming key access queries to an existing index built on the correlated columns. This is achieved through the Tiered Regression Search Tree (TRS-Tree), a succinct, ML-enhanced data structure that performs fast curve fitting to adaptively and dynamically capture both column correlations and outliers. Our extensive experimental study in two different RDBMSs have confirmed that Hermit can significantly reduce space consumption with limited performance overhead, especially when supporting complex range queries.
Highlight
Publications: SIGMOD 2019 (research), PVLDB 2019 (demo)
Collaborators: Yingjun Wu, Yuanyuan Tian, Ronald Barber, and Richard Sidle (IBM Almaden Research Center)
Presentation
I presented Hermit index at Microsoft Research. Here is the presentation video on Microsoft Research website: Hermit at MSR
Jia Yu
Co-founder
Jia Yu is a co-founder of Wherobots Inc.. Jia is the creator of Apache Sedona and was a Tenure-Track Assistant Professor of Computer Science at Washington State University from 2020 to 2023. Jia’s research interests include database systems, distributed data systems and geospatial data management.